1.1. CSE 599W Systems for ML @ UW
Simpler version of CS 294 @ Berkeley. (quarter vs. semester)
System aspect of deep learning: faster training, efficient serving, lower memory consumption.
CSE 599W - Systems for ML - 辛酸阅读记录
1.1.1. Intro to DL
Convolution = Spatial Locality + Sharing
Evolution of CNN
- LeNet (LeCun, 1998) - Basic structures: convolution, max-pooling, softmax
- Alexnet (Krizhevsky et.al 2012) - ReLU, Dropout
- GoogLeNet (Szegedy et.al. 2014) - Multi-independent pass way (Sparse weight matrix)
- Inception BN (Ioffe et.al 2015) - Batch normalization
- Residual net (He et.al 2015) - Residual pass way
1.1.2. Overview of DL System
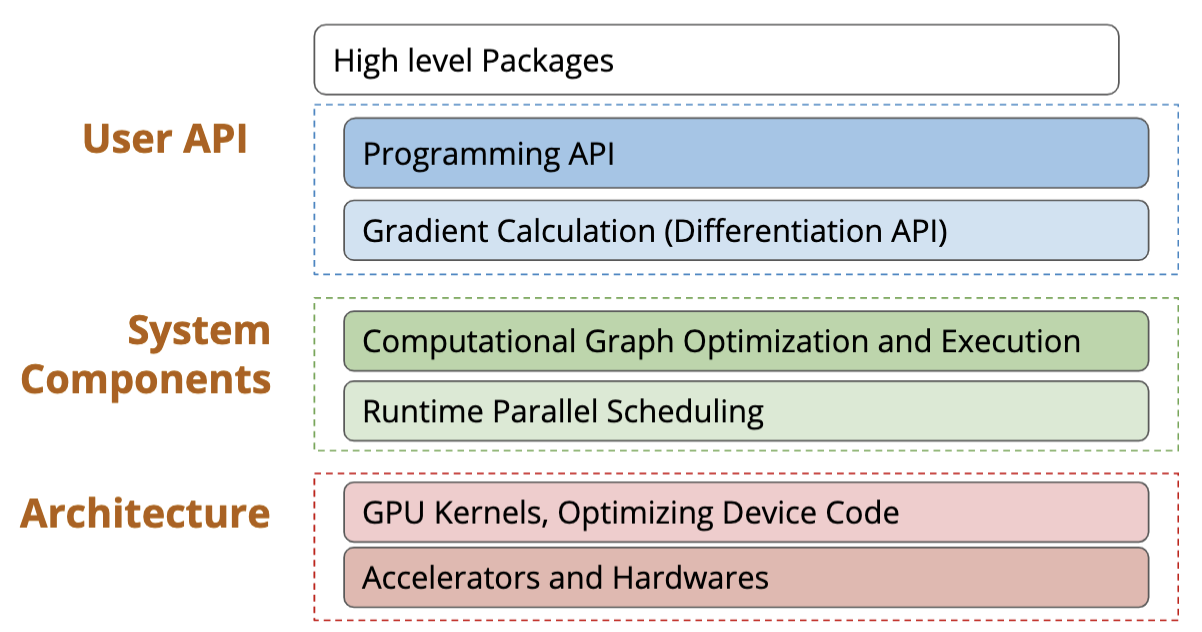
User API
Logistic regression in Numpy
- Computation in Tensor Algebra
softmax(np.dot(batch_xs, W)) - Manually calculate the gradient
y_grad = y - batch_ys,W_grad= np.dot(batch_xs.T, y_grad) - SGD Update Rule
W = W - learning_rate *W_grad
Logistic regression in Tinyflow
- Loss function declaration
- Automatic differentiation
- Real execution
sess.run
Imperative vs symbolic (declarative)
- Imperative-style programs perform computation as you run them - numpy
- Symbolic: define the function first, then compile them - Tinyflow
The declarative language - computation graph
- Nodes = operation, edge = dependency between ops
- Execution only touches needed subgraph
System Components
Computation graph optimization
- E.g. deadcode elimination
- Memory planning and optimization
Parallel scheduling
- Code need to run parallel on multiple devices and worker threads
- Detect and schedule parallelizable patterns
Supporting more hardware backends
- Each Hardware backend requires a software stack
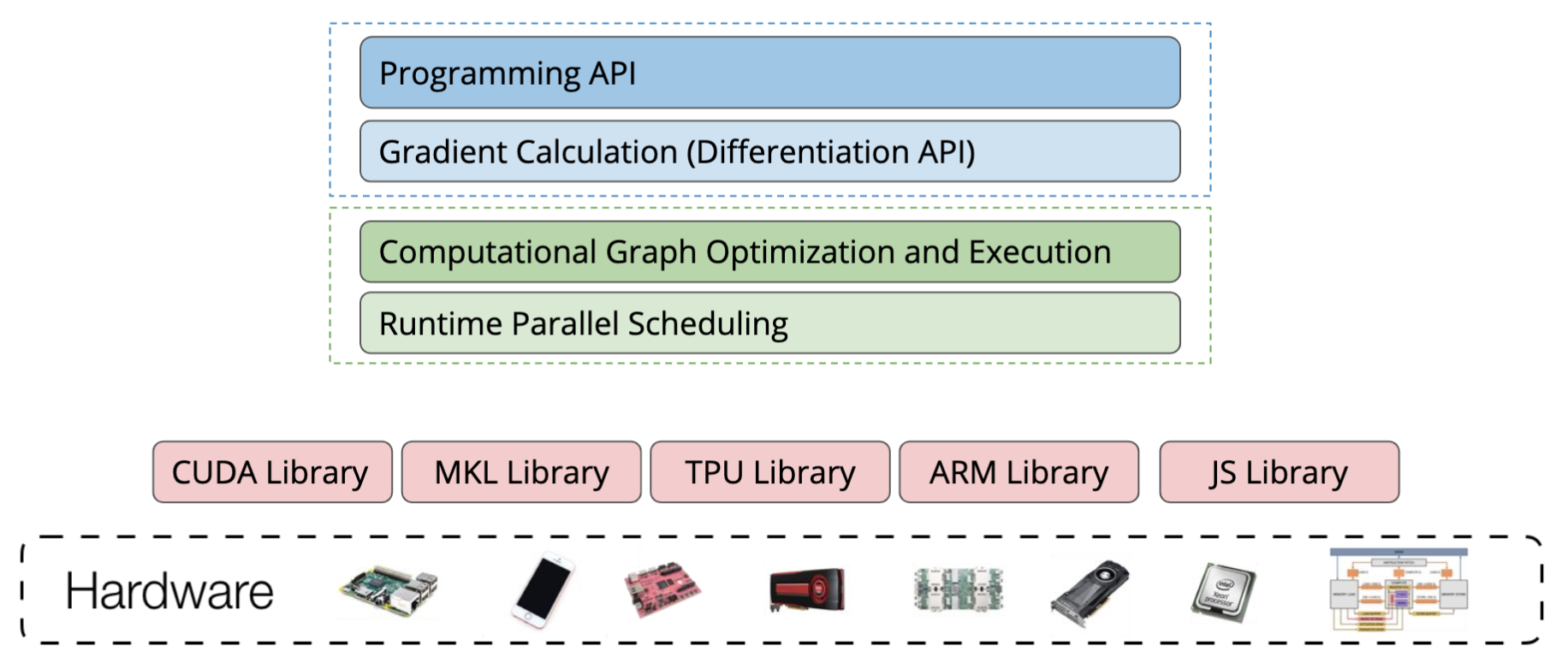
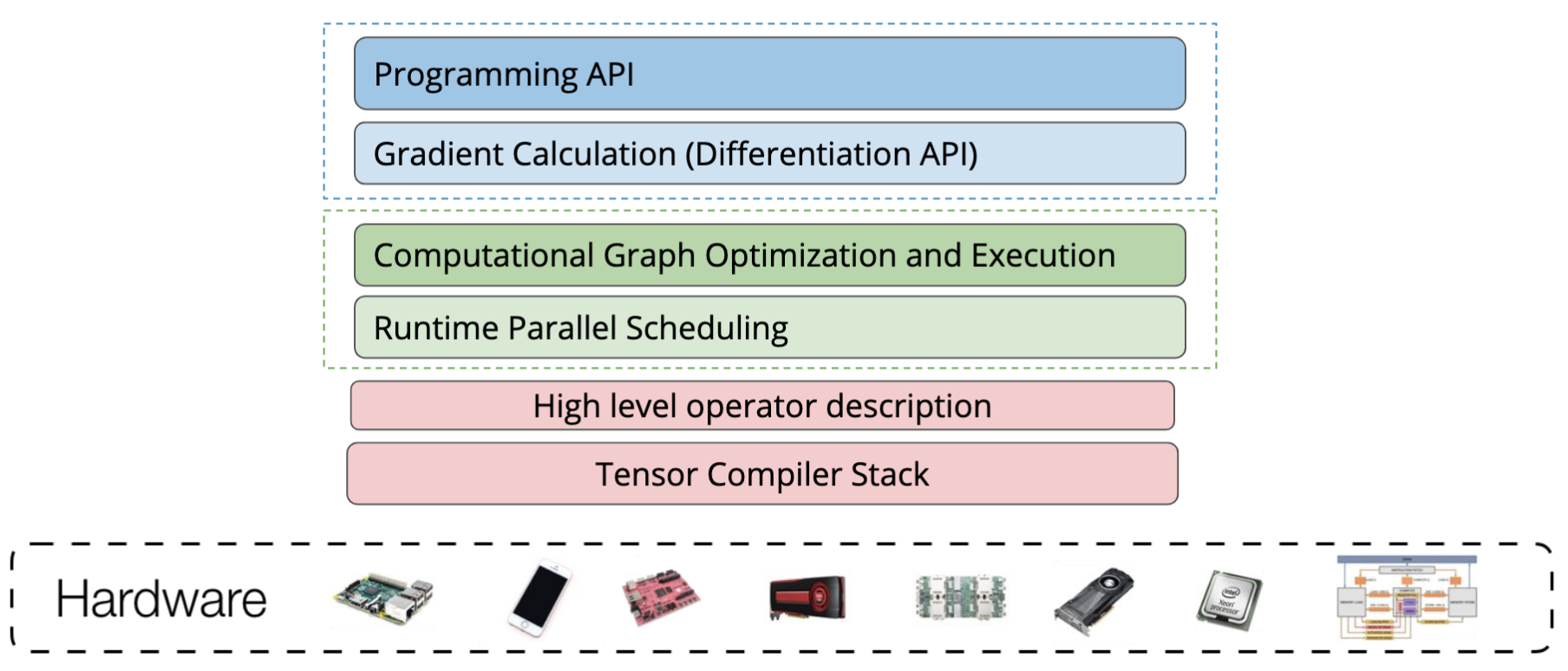
- New trend - compiler based approach
1.1.3. Backpropagation and Automatic Differentiation
Symbolic differentiation
- Input formula is a symbolic expression tree (computation graph)
- Implement differentiation rules, e.g. sum rule, product rule, chain rule
- Cons
- For complicated functions, the resultant expression can be exponentially large.
- Wasteful to keep around intermediate symbolic expressions if we only need a numeric value of the gradient in the end
- Prone to error
Numerical differentiation
Automatic differentiation (autodiff)
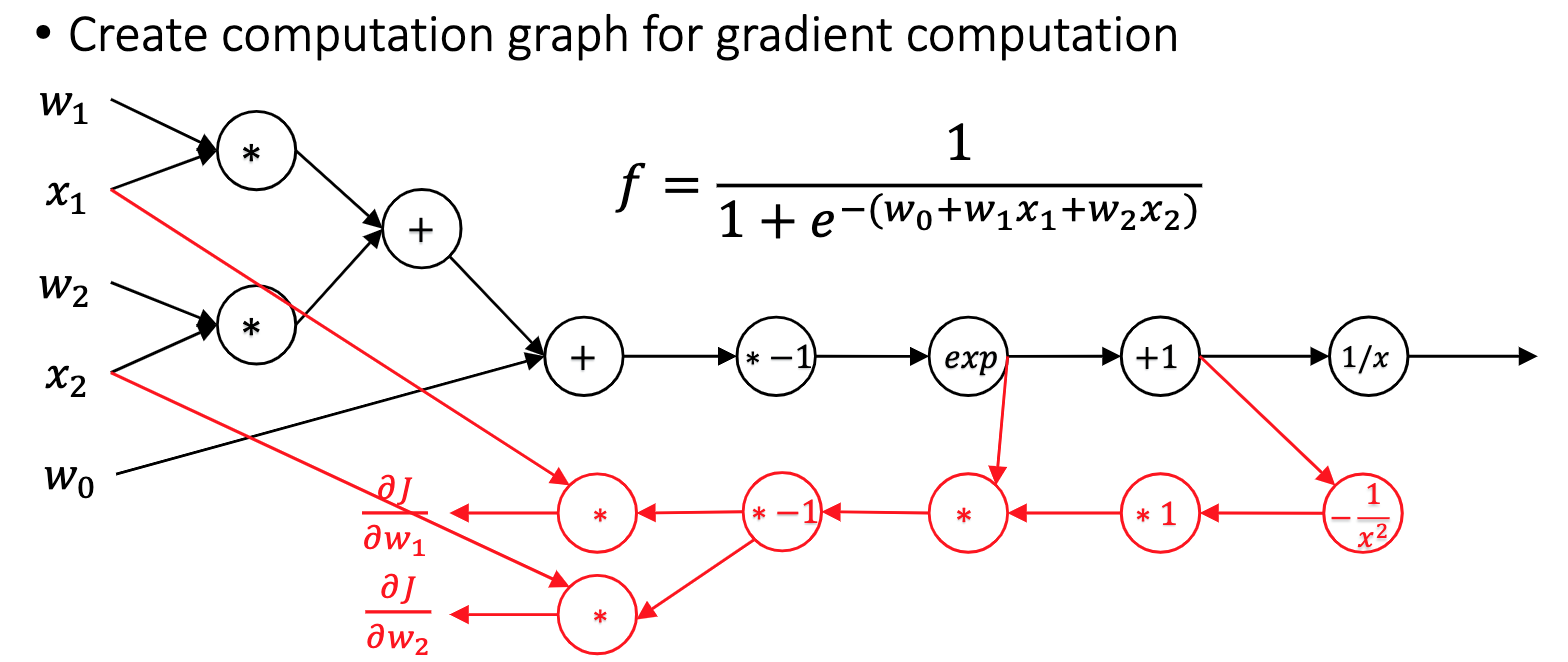
AutoDiff algorithm
def gradient(out):
node_to_grad[out] = 1
nodes = get_node_list(out)
for node in reverse_topo_order(nodes):
grad <- sumpartial adjoints from output edges
input_grads <- node.op.gradient(input, grad) for input in node.inputs
add input_gradsto node_to_grad
return node_to_grad
Recap
- Numerical differentiation
- Tool to check the correctness of implementation
- Backpropagation
- Easy to understand and implement
- Bad for memory use and schedule optimization
- Automatic differentiation
- Generate gradient computation to entire computation graph
- sBetter for system optimization
1.1.4. Hardware Backends: GPU
GPU arch
Streaming multiprocessors (SM)
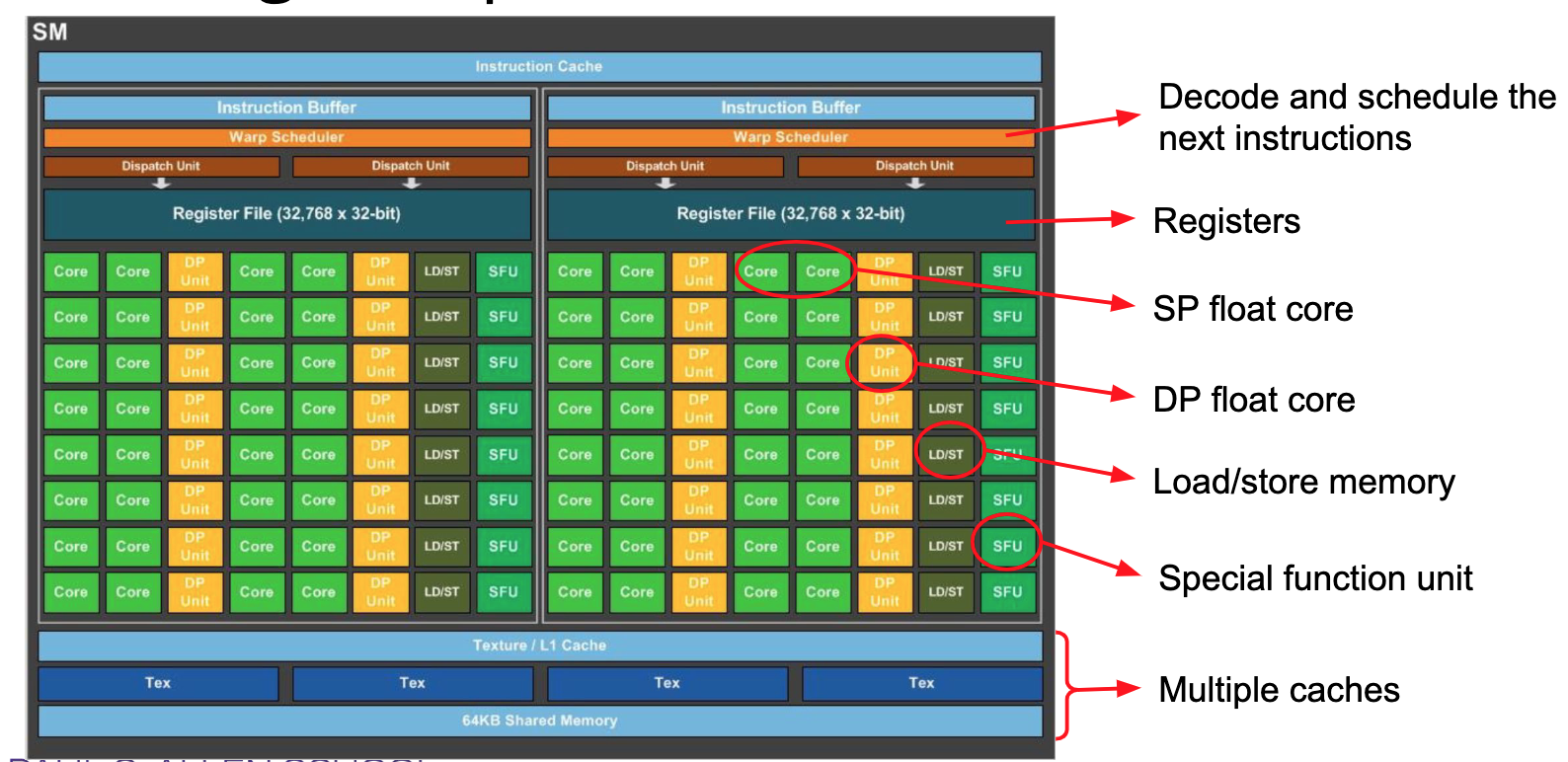
GPU arch

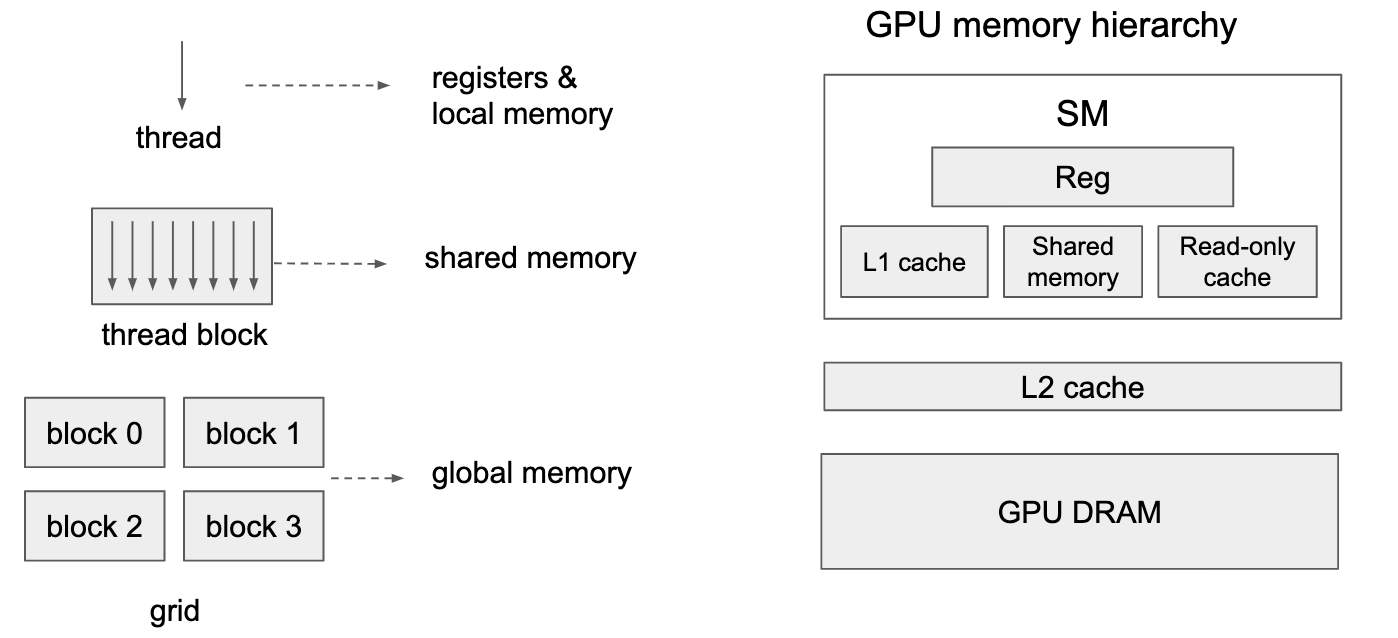
Memory hierarchy
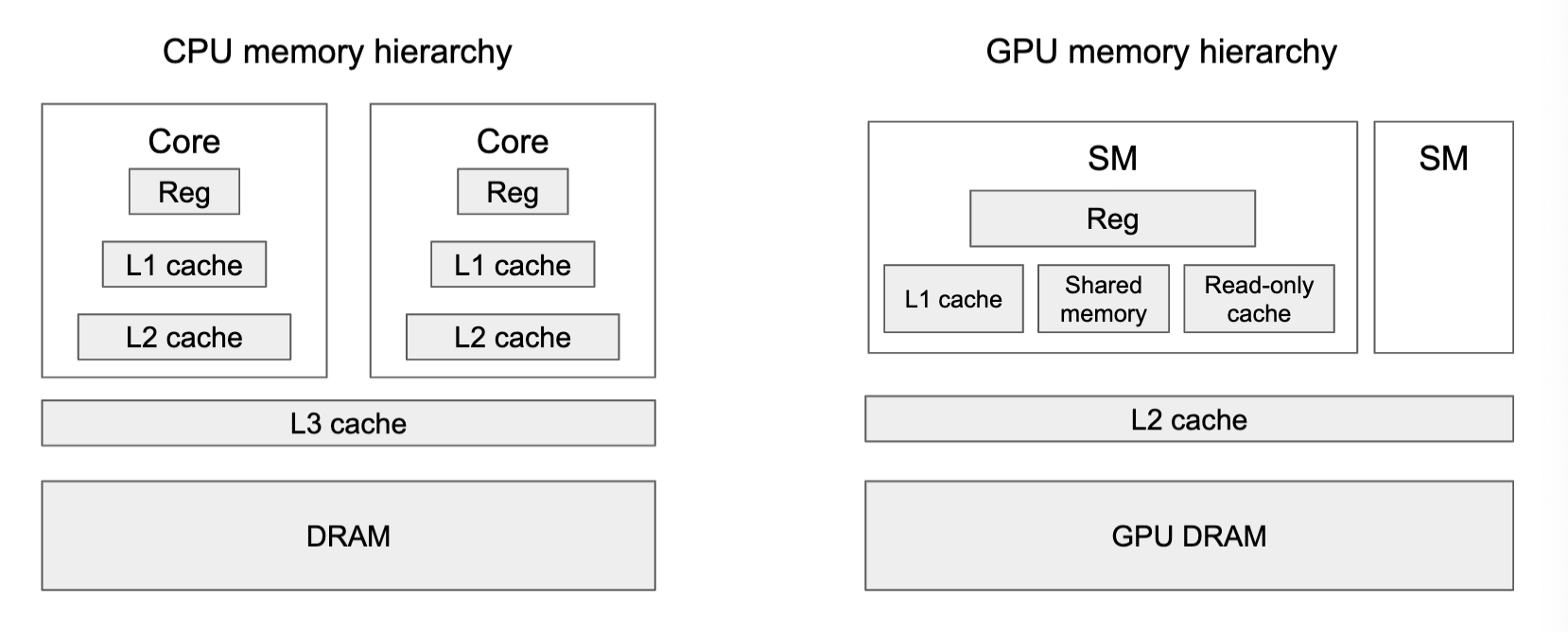

- GPU has more registers than L1 cache
- L1 cache controlled by programmer
GPU memory latency
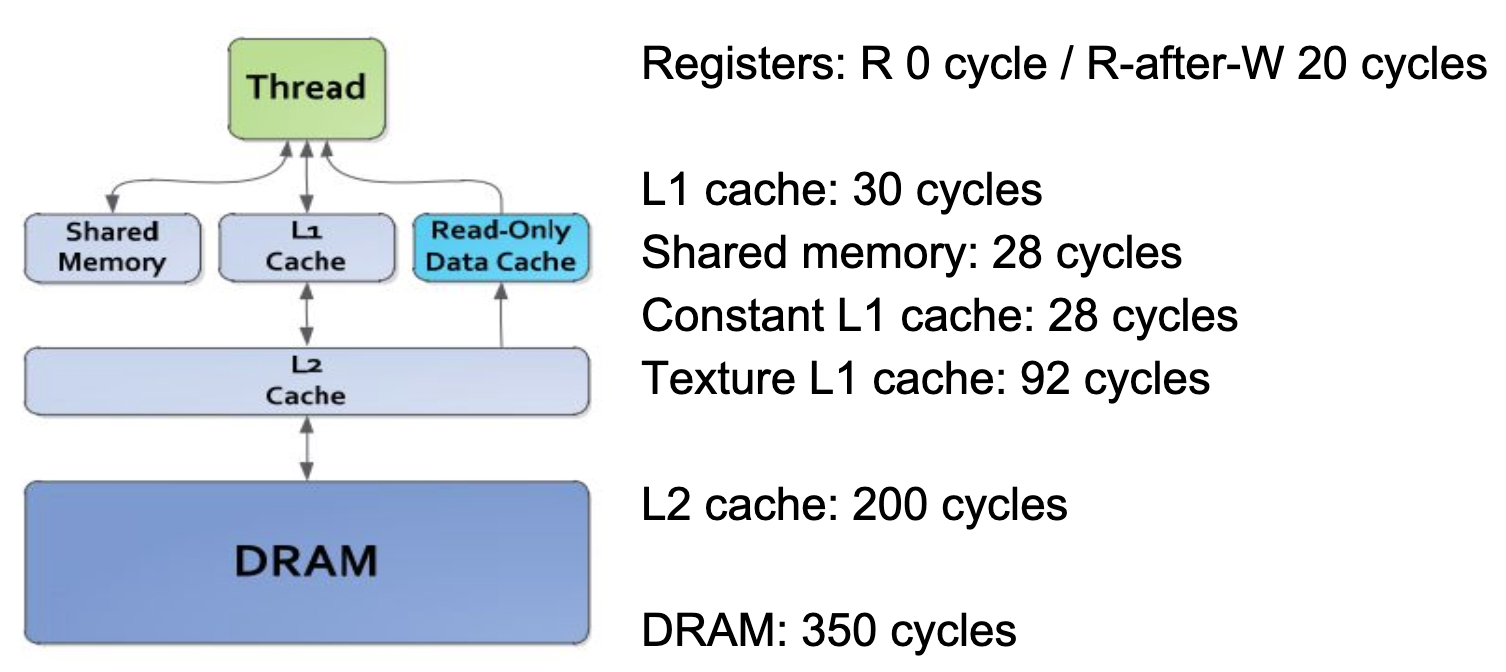
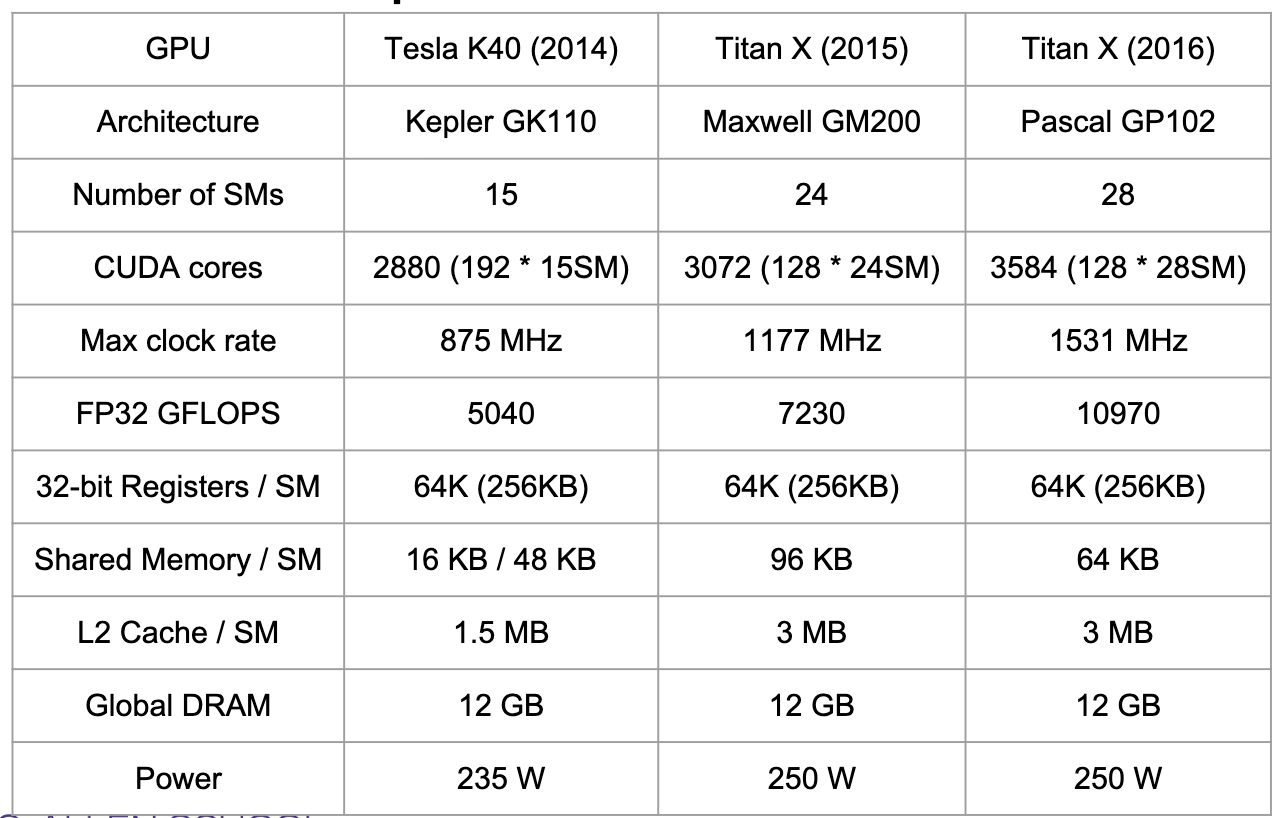
Nvidia GPU comparison
CUDA
Programming model - SIMT
- Single instruction, multiple threads
- Programmer writes codes for a single thread in simple C program - All threads execute the same code, but can take different paths
- Threads are grouped into a block - threads within the same block can synchronize execution
- Blocks are grouped into a grid - blocks are independently scheduled on the GPU, can be executed a=in any order
- A kernel is executed as a grid of blocks of threads.
- One thread -> thread block -> grid = kernel
Kernel execution
- Each block is executed by one SM and does not migrate
- Several concurrent blocks can reside on one SM depending on block's memory requirement and the SM's memory resources
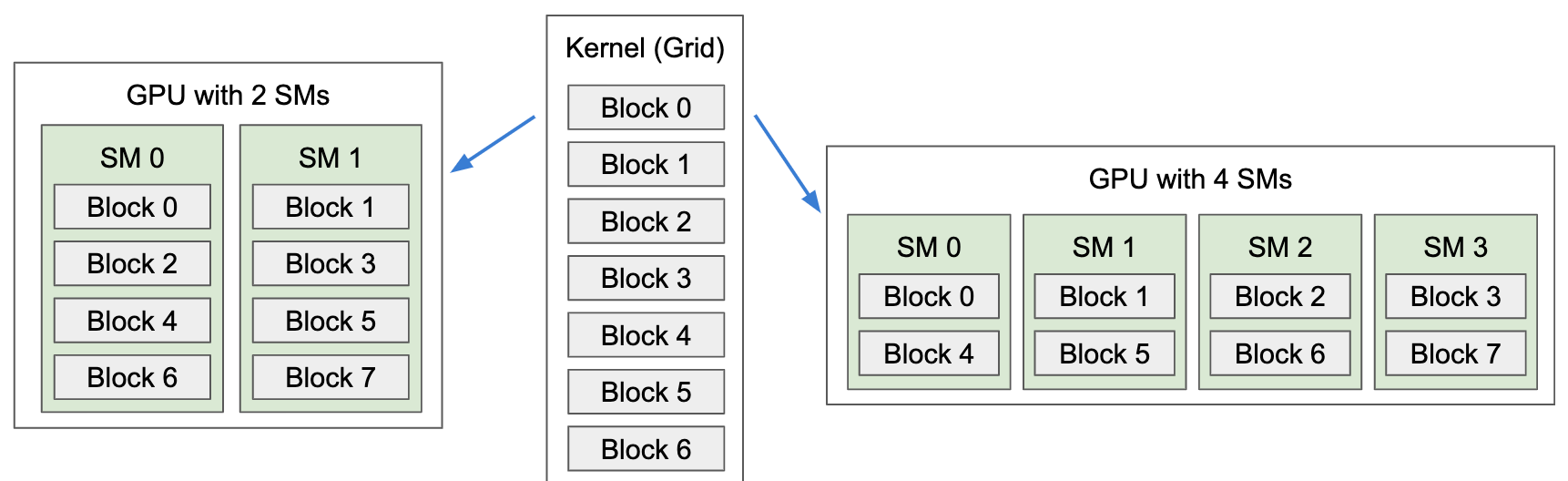
- A warp consists of 32 threads - basic schedule unit in kernel execution
- A thread block consists of 32-thread warps
- Each cycle, a warp scheduler selects one ready warp and dispatch the warp to CUDA cores to execute?
Thread hierarchy & memory hierarchy
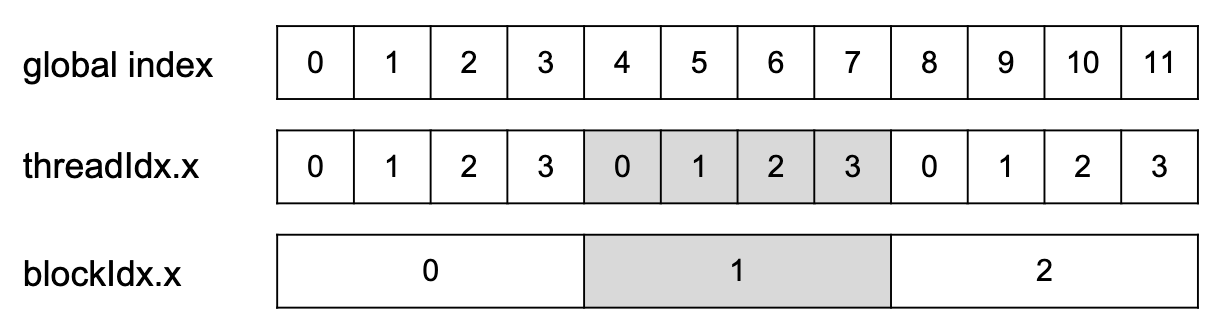
Global index = BlockDim * BlockIDx + ThreadIdx
Efficient GPU kernels
GEMM, reduction sum
Tips for high performance
- Use existing libraries, which are highly optimized, e.g. cublas, cudnn
- Use nvprof or nvvp (visual profiler) to debug the performance
- Use high level language to write GPU kernels.
1.1.5. Optimize for Hardware Backends
Gap between computation graph and hardware
GEMM example - memory reuse
- Generalize to GPU - reuse among threads
Optimizations = too many variant of operators
- Different tiling patterns, fuse patterns, data layout, hardware backends
Explore code generation approach
- Intermediate representation (between computation graph and code) - also called domain specific language
1.1.6. DSL
Automatic code generation TVM stack
Computation graph as IR
- Represent high-level DL computations
- Effective equivalent transformations to optimize the graph
- Approach taken by TensorFlow XLA, Intel NGraph, Nvidia TensorRT
XLA - TensorFlow compiler
- Constant shape dimension, data layout is specific
- Ops are low-level tensor primitives - map, reduce, broadcast, convolution, reduce window
TensorRT - Rule based fusion
- Simple graph-based element wise kernel generator
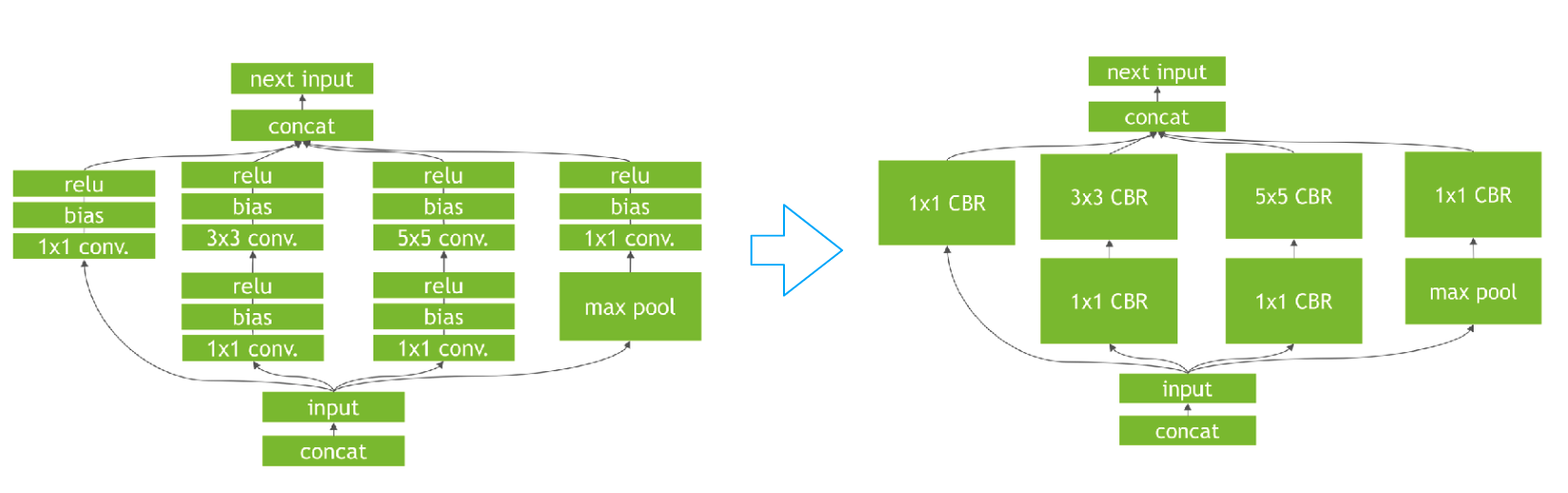
Computation graph optimizations
- Need to build and optimize operators for each hardware, variant of layout, precision, threading pattern
- Tensor expression language
- Emerging tools using tensor expression language
- Halide - image processing language
- Loopy - python based kernel generator
- TACO - sparse tensor code generator
- Tensor comprehension
Schedule - Tensor expression to code
- Key idea introduced by Halide - separation of compute and schedule
- Key challenge - good space of schedule
- Should contain any knobs that produce a logically equivalent program that runs well on backend models
- Must contain common manual optimizations patterns
- Need to actively evolve to incorporate new techniques
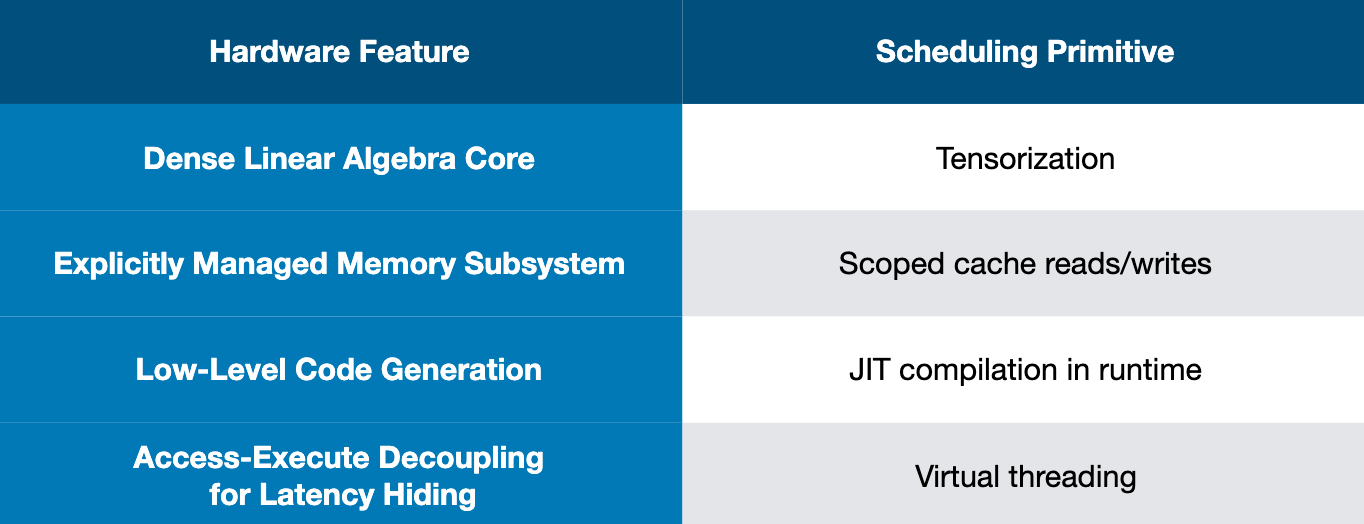
TVM schedule primitives
- Primitives in prior works Halide, Loopy - loop transformations, thread bindings, cache locality
- New primitives for GPU accelerations - thread cooperation, tensorization, latency hiding, ... (still evolving)
Global view of TVM stack
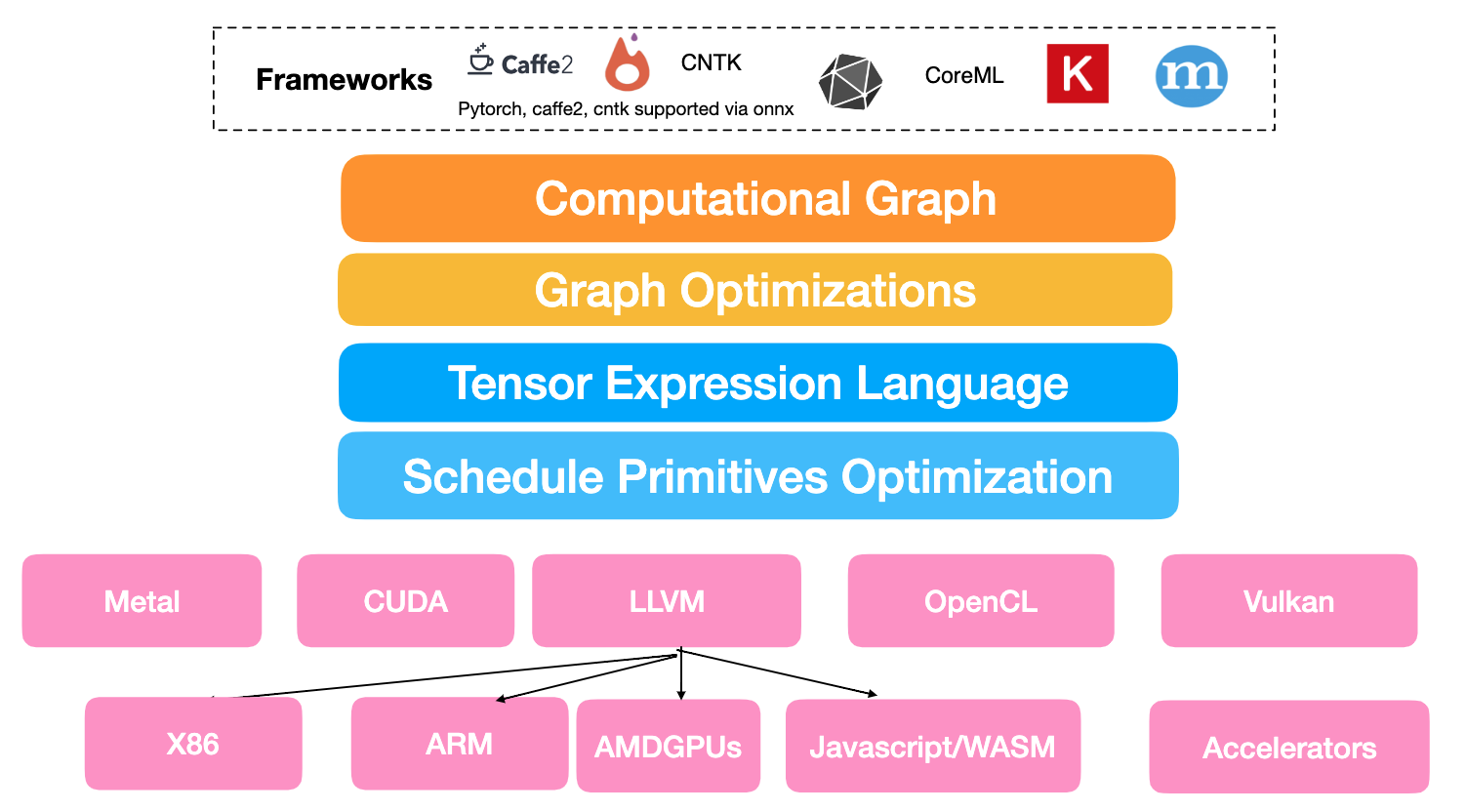
- High level compilation frontend - on languages and platforms you choose
- Program your phone with python from your laptop

A lot of open problems
- Optimize for NLP models like RNN, attention
- High dimensional convolutions
- Low bit and mix precision kernels
- More primitive support for accelerators
1.1.7. Hardware Specialization in DL


What make TPUs efficient? (- Shows 30-80x improved TOPS/Watt over K80)
- Integer inference (saves 6-30x energy over 16bit FP)
- Large amount of MACs (25x over K80)
- Large amount of on-chip memory (3.5x over K80)
HW/SW co-design
- Tensorization
- Memory architecting
- Data type - Reducing type width can result in a quadratic increase of compute resources, and linear increase of storage/bandwidthBut it also affects classification accuracy
CISC/RISC ISA
- Goal: Provide the right tradeoff between expressiveness and code compactness
- Use CISC-ness to describe high-level operation (LD, ST, GEMM, ALU)
- Use RISC-ness to describe low-level memory access patterns
- Micro-op kernels are stored in a local micro op cache to implement different operators
Latency hiding - work partitioning and explicit dependence graph execution (EDGE) unlocks pipeline parallelism to hide the latency of memory accesses
Optimization stack for DL accelerators
1.1.8. Memory Optimization
State-of-art models can be resource bound - The maximum size of the model we can try is bounded by total RAM available of a Titan X card (12G)
Build an executor for a given computation graph
- Allocate temp memory for intermediate computation
- Traverse and execute the graph by topological order - temporary space linear to # of ops
Dynamic memory allocation
- Allocate when needed
- Recycle when a memory is not needed - memory pool
- Useful for both declarative and imperative executions
Static memory planing
- Plan for reuse ahead of time
- Analog - register allocation algorithm in compiler
Common pattern of memory planning
- Inplace store the result in the input (inplace)
- Optimizations - Store the result in the input; Works if we only care about the final result
- Pitfalls - we can only do inplace if result op is the only consumer of the current value
- Normal memory sharing - reuse memory that is no longer needed (co-share)
Concurrency (heuristics) vs memory optimizations
Sub-linear memory complexity (> sharing > inplace?)
- If we check point every K steps on a N layer network
- Memory cost = cost per segment + cost to store results = O(K) + O(N/K) 分块
- We can get sqrt(N) memory cost plan with one additional forward pass (25% overhead)
Takeaways
- Computation graph is a useful tool for tracking dependencies
- Memory allocation affects concurrency
- We can trade computation for memory to get sub-linear memory plan
1.1.9. Parallel Scheduling
Model parallel training
- Map parts of workload to different devices
- Require special dependency patterns (wave style, e.g. LSTM)
Data parallelism
- Train replicated version of model in each machine
- Synchronize the gradient
Parallel program is hard to write. We need an automatic scheduler.
Goal of scheduler interface
- Schedule any resources - data flow, memory recycle, random number generator, network communication
- Schedule any operation
DAG based scheduler
- Explicit push ops and their dependencies
- Can reuse computation graph structure
- Useful when all results are immutable
- Used in typical frameworks (e.g. Tensorflow)
Mutation aware scheduler
- Can solve these problems much easier than DAG based scheduler
- Tag each resource -> pack refs to related things into execution function via closure -> push ops
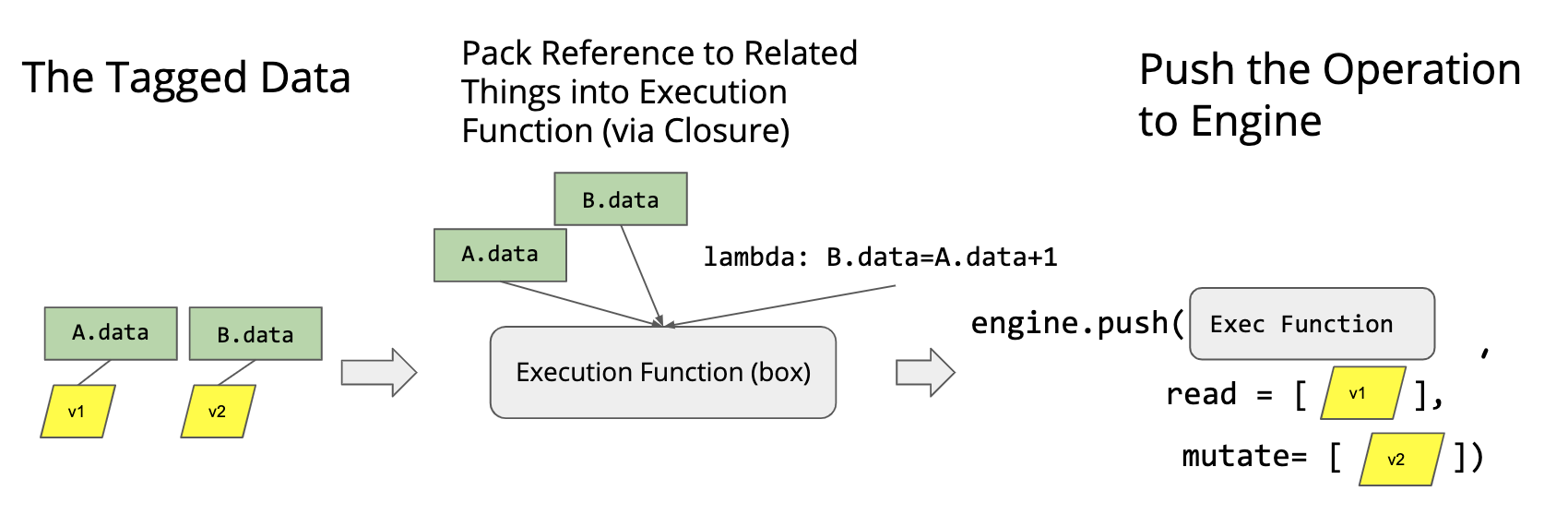
Queue based Implementation of scheduler
Take aways
- Automatic scheduling makes parallelization easier
- Mutation aware interface to handle resource contention
- Queue based scheduling algorithm
1.1.10. Distributed Training & Communication Protocols
How to do synchronization over network?
Allreduce - collective reduction
- Reduction on common connection topo - all-to-all, ring, tree-shape
- Libs, GPUDirect and RDMA
- Schedule Allreduce asynchronously
Parameter server
1.1.11. Model Serving
Model serving constraints
- Latency
- Batch size cannot be as large as possible when executing in the cloud
- Can only run lightweight model in the device
- Resource
- Battery/memory limit for the device
- Cost limit for using cloud
- Accuracy
- Some loss is acceptable by using approximate models
- Multi-level QoS
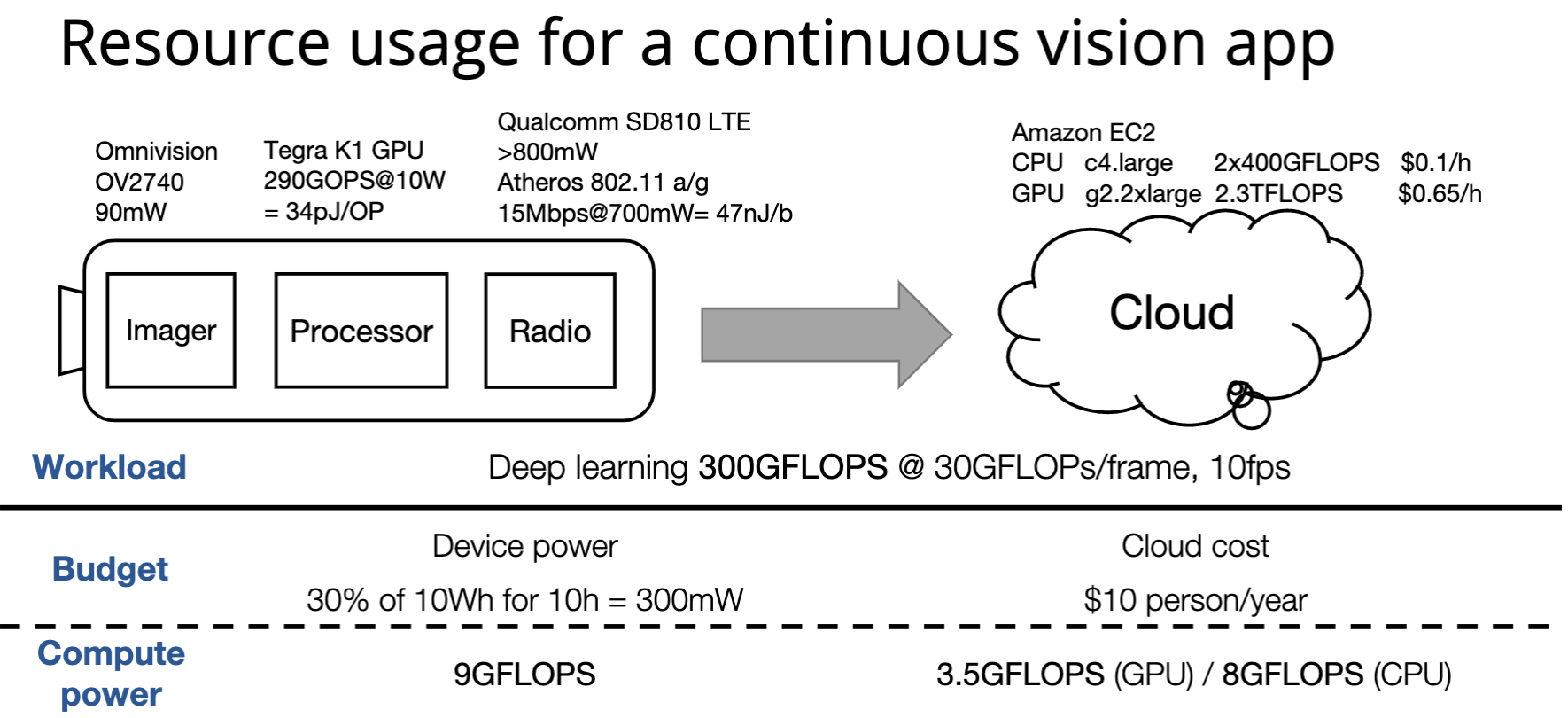
Model compression - Tensor(matrix) decomposition, network pruning, quantization, smaller model (knowledge distillation)
Network pruning - deep compression, prune the connections, weight sharing
Knowledge distillation: use a teacher model (large model) to train a student model (small model)
Serving system
- Goals
- High flexibility for writing applications
- High efficiency on GPUs
- Satisfy latency SLA
- Challenges
- Provide common abstraction for different frameworks
- Achieve high efficiency
- Sub-second latency SLA that limits the batch size
- Model optimization and multi-tenancy causes long tail
Nexus: efficient neural network serving system
- Frontend runtime library allows arbitrary app logic
- Packing models to achieve higher utilization
- A GPU scheduler allows new batching primitives
- A batch-aware global scheduler allocates GPU cycles for each mode
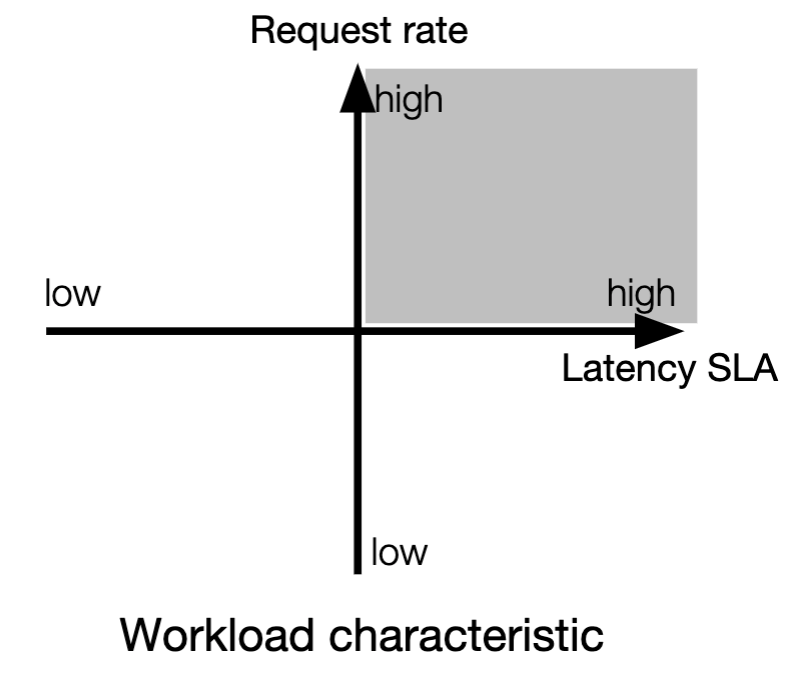
High efficiency
- High request rate, high latency SLA workload - saturate GPU efficiency by using large batch size
- High request rate, low latency SLA workload - Suppose we can choose a different batch size for each op (layer), and allocate dedicated GPUs for each op. (split batching)
- Low request rate, high latency SLA workload
- This type of workload cannot saturate GPU in temporal domain
- Execute multiple models on one GPU; use larger batch size as latency is reduced and predictive
- Low request rate, low latency SLA workload
- If saturate GPU in temporal domain due to low latency: allocate dedicated GPU(s)
- If not: can use multi-batching to share GPU cycles with other models
1.1.12. How PyTorch Optimized DL Computations
Compute with PyTorch
Performance Improvements
